Now that we have a basic understanding of the document domain, we can turn again to developing a data model for Haystack. Abstractly, our goal is to map what we have learned the document model into usable data structures.
When discussing the query model previously (see
Section  ), we found two components that were part of
every query, the information need, and hints. Hints were used to
narrow down the results produced by the information system to satisfy
the information need. In Haystack we would like to be able to handle
three distinct types of hints:
), we found two components that were part of
every query, the information need, and hints. Hints were used to
narrow down the results produced by the information system to satisfy
the information need. In Haystack we would like to be able to handle
three distinct types of hints:
These hints naturally map to the three components of document state
described previously. Alternatively, they also map to the three
information system types: information retrieval, databases, and
hypertext, respectively. Table describes the
relationships between all the models we have described so far. From
left to right, the models become increasingly concrete. The document
model represents ideas that will become instantiated in the
Straw model we will presently describe. Our motivation is to
build an efficient and useful implementation that most accurately maps
our abstract models into reality.
| Document Model | Straw Model | Information System | In Haystack |
| Internal state | Term ties | Information Retrieval | Any IR system |
| External state | Intra-document ties | Database | Lore |
| Relationships to other documents | Inter-document ties | Hypertext | Lore |
Now that we have a goal in mind, it is possible to build a data structure representing the document model. We are additionally interested in developing the data structure within an object-oriented environment. We define objects to be instantiation of a particular class. A class is a definition of an object containing both data members and methods. Data members and methods simply correspond to variables and functions. Classes can be extended in a hierarchical fashion, where an extension inherits certain public data members and methods of its ancestors.
The Haystack data model is essentially a graph structure where the
nodes (vertices) and ties are first-class objects.
First-class implies that an object can be named, exist on its own, and
be passed to, and returned by functions. Both ties and nodes extend a
specific class. In adherence to our namesake we call this class
Straw.
Straw will be discussed in great detail in
Chapter , but for now regarding Straw objects as
nodes will suffice.
are first-class objects.
First-class implies that an object can be named, exist on its own, and
be passed to, and returned by functions. Both ties and nodes extend a
specific class. In adherence to our namesake we call this class
Straw.
Straw will be discussed in great detail in
Chapter , but for now regarding Straw objects as
nodes will suffice.
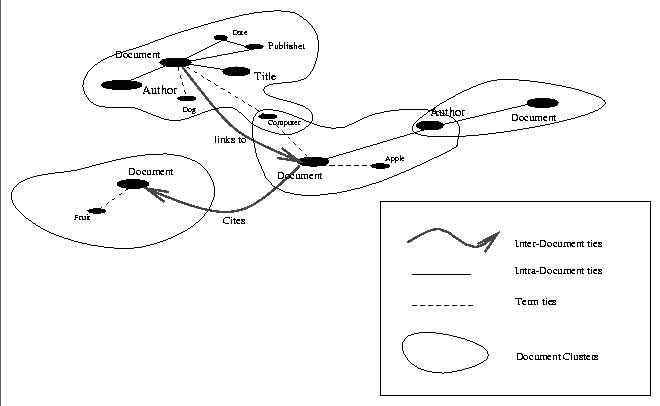
Figure: The Straw Model in Haystack
The graph structure in Figure is a possible (but
simplistic) representation of Straws. This model shows Document
straws connected to a variety of other objects: publisher, title,
author, date, and other documents. Between straws there are
three types of connections:
inter-document ties, intra-document ties, and term
ties. Although in the implementation of Haystack
we don not make these distinctions explictly, this categorization
will help in the present discussion.
Intra-document ties represent a mapping to what we have previously
called the external state or metadata of an object. For example, we
can connect an author node to the document node by means of an
intra-document tie. To partition different documents we will also
draw a virtual boundry around clusters of straws connected by
intra-document ties and call this a document cluster. In the
figure we see one central document node for each document cluster. In
Haystack we call this document node a HaystackDocument
object. The nodes that have some associated data with them we will
call a Needle. For example, we can have an author
node/Needle which contains the data ``David'' (with the
obvious implication that David is the author). We'll return to both
of these objects in Chapter when we describe the
implementation of Haystack data model in full.
Inter-document ties represent associations between different document clusters. For example, if one document cites another, we can draw the cites connection between the two. Alternatively, if one document is a web page that links to another, we can use the relation, links to. This type of linking represents the hypertext aspect of the system.
Finally, term ties allow us to connect terms held within the document to the document cluster. That is, if the word ``dog'' appears in a document, we connect a node holding the word dog to to the document by means of a term tie. Note that we are not interested in the word ``dog'' alone, but rather the concept of a ``dog.'' The word in the document may be ``dog'' but the user may remember ``canine'' or ``pooch.'' This implies some semantic understanding of the content of a term straw.
With this model, we are now capable of describing documents in a way that appropriately maps the memory and document models. We propose that it is now possible to both describe objects and to query for them in a powerful manner that is consistent with the way information exists in the ``real'' world.